

1·
2 days agoMore like the straw that broke the camel’s back. And a sign that Microsoft’s behaviour is still the same as it was in IE times.

The catarrhine who invented a perpetual motion machine, by dreaming at night and devouring its own dreams through the day.
More like the straw that broke the camel’s back. And a sign that Microsoft’s behaviour is still the same as it was in IE times.
I know that this expression desensitises people to something serious, but it describes Microsoft - the “it”/corporation - perfectly: rapist mentality. It shows how eager Microsoft is to disregard consent, users saying “no, I don’t want it”, and to force itself over the users as long as it gets some benefit out of it.
Including new obnoxious advertisement slots into an already released product - one that you paid for - is only a result of that mentality.
Those mistakes would be easily solved by something that doesn’t even need to think. Just add a filter of acceptable orders, or hire a low wage human who does not give a shit about the customers special orders.
That wouldn’t address the bulk of the issue, only the most egregious examples of it.
For every funny output like “I asked for 1 ice cream, it’s giving me 200 burgers”, there’s likely tens, hundreds, thousands of outputs like “I asked for 1 ice cream, it’s giving 1 burger”, that sound sensible but are still the same problem.
It’s simply the wrong tool for the job. Using LLMs here is like hammering screws, or screwdriving nails. LLMs are a decent tool for things that you can supervision (not the case here), or where a large amount of false positives+negatives is not a big deal (not the case here either).
Next on the news: “Hitler ate bread.”
I’m being cheeky, but I don’t genuinely think that “Nazi are using a tool that is being used by other people” is newsworthy.
Regarding the blue octopus, mentioned in the end of the text: when I criticise the concept of dogwhistle, it’s this sort of shit that I’m talking about. I don’t even like Thunberg; but, unless there is context justifying the association of that octopus plushy with antisemitism, it’s simply a bloody toy dammit.

Yeah, it’s actually good. People use it even for trivial stuff nowadays; and you don’t need a pix key to send stuff, only to receive it. (And as long as your bank allows you to check the account through an actual computer, you don’t need a cell phone either.)
Perhaps the only flaw is shared with the Asian QR codes - scams are a bit of a problem, you could for example tell someone that the transaction will be a value and generate a code demanding a bigger one. But I feel like that’s less of an issue with the system and more with the customer, given that the system shows you who you’re sending money to, and how much, before confirmation.
I’m not informed on Tikkie and Klarna, besides one being Dutch and another Swedish. How do they work?
Brazil ended with a third system: Pix. It boils down to the following:
The “key” in question can be your cell phone number, physical/juridical person registre number, e-mail, or even a random number. You can have up to five of them.
Regarding dynamic codes, it’s also possible to generate a key or QR code that applies to a single transaction. Then the value to be paid is already included.
Frankly the system surprised me. It’s actually good and practical; and that’s coming from someone who’s highly suspicious of anything coming from the federal government, and who hates cell phones. [insert old man screaming at clouds meme]
Do you mind if I address this comment alongside your other reply? Both are directly connected.
I was about to disagree, but that’s actually really interesting. Could you expand on that?
If you want to lie without getting caught, your public submission should have neither the hallucinations nor stylistic issues associated with “made by AI”. To do so, you need to consistently review the output of the generator (LLM, diffusion model, etc.) and manually fix it.
In other words, to lie without getting caught you’re getting rid of what makes the output problematic on first place. The problem was never people using AI to do the “heavy lifting” to increase their productivity by 50%; it was instead people increasing the output by 900%, and submitting ten really shitty pics or paragraphs, that look a lot like someone else’s, instead of a decent and original one. Those are the ones who’d get caught, because they’re doing what you called “dumb” (and I agree) - not proof-reading their output.
Regarding code, from your other comment: note that some Linux and *BSD distributions banned AI submissions, like Gentoo and NetBSD. I believe it to be the same deal as news or art.
Sometimes. Sometimes it’s more accurate than anyone in the village.
So does the village idiot. Or a tarot player. Or a coin toss. And you’d still need to be a fool if your writing relies on the output of those three. Or of a LLM bot.
And it’ll be reliably getting better.
You’re distorting the discussion from “now” to “the future”, and then vomiting certainty on future matters. Both things make me conclude that reading your comment further would be solely a waste of my time.
3. If you lie about it and get caught people will correctly call you a liar, ridicule you, and you lose trust. Trust is essential for content creators, so you’re spelling your doom. And if you find a way to lie without getting caught, you aren’t part of the problem anyway.
For writers, that “no AI” is not just the equivalent of “100% organic”; it’s also the equivalent as saying “we don’t let the village idiot to write our texts when he’s drunk”.
Because, even as we shed off all paranoia surrounding A"I", those text generators state things that are wrong, without a single shadow of doubt.

As I joked in another thread about the same topic: eventually the Fødevarestyrelsen will recall food products packed in plastic, not due to environmental concerns, but because it assumes that people will eat the plastic.
There’s no way to buy this sort of ultrahot ramen by mistake. And even if you did, a single slurp is all that you need to know that it’s too hot for you.
Think on the available e-books as a common pool, from the point of view of the people buying them: that pool is in perfect condition if all books there are DRM-free, or ruined if all books are infested with DRM.
When someone buys a book with DRM, they’re degrading that pool, as they’re telling sellers “we buy books with DRM just fine”. And yet people keep doing it, because:
So in a lot of situations, buyers beeline towards the copy with DRM, as it’s individually more convenient, even if ruining the pool for everyone in the process. That’s why I said that it’s a tragedy of the commons.
As you correctly highlighted that model relies on the idea that the buyer is selfish; as in, they won’t care about the overall impact of their actions on the others, only on themself. That is a simplification and needs to be taken with a grain of salt, however note that people are more prone to act selfishly if being selfless takes too much effort out of them. And those businesses selling you DRM-infested copies know it - that’s why they enclose you, because leaving that enclosure to support DRM-free publishers takes effort.
I guess in the end we are talking about the same
I also think so. I’m mostly trying to dig further into the subject.
So the problem is not really consumer choice, but rather that DRM is allowed in its current form. But I admit that this is a different discussion
Even being a different discussion, I think that one leads to another.
Legislating against DRM might be an option, but easier said than done - governments are specially unruly, and they’d rather support corporations than populations.
Another option, as weird as it might sound, might be to promote that “if buying is not owning, pirating is not stealing” discourse. It tips the scale from the business’ PoV: if people would rather pirate than buy books with DRM, might as well offer them DRM-free to increase sales.
Does this mean that I need to wait until September to reply? /jk
I believe that the problem with the neolibs in this case is not the descriptive model (tragedy of the commons) that they’re using to predict a potential issue; it’s instead the “magical” solution that they prescribe for that potential issue, that “happens” to align with their economical ideology, while avoiding to address that:
And while all models break if you look too hard at them, I don’t think that it does in this case - it explains well why individuals are buying DRM-stained e-books, even if this ultimately hurts them as a collective, by reducing the availability of DRM-free books.
(And it isn’t like you can privatise it, as the neolibs would eagerly propose; it is a private market already.)
I’m reading the book that you recommended (thanks for the rec, by the way!). Under a quick glance, it seems to propose self-organisation as a way to solve issues concerning common pool resources; it might work in plenty cases but certainly not here, as there’s no way to self-organise people who buy e-books.
And frankly, I don’t know a solution either. Perhaps piracy might play an important and positive role? It increases the desirability of DRM-free books (you can’t share the DRM-stained ones), and puts a check on the amount of obnoxiousness and rug-pulling that corporations can submit you to.
I know that I shouldn’t, but here’s what I think about this whole deal, illustrated with a single image macro:

Get wrecked, Microsoft.
I think that the article does a good job highlighting how much of a trainwreck this is, because Microsoft is not to be trusted. The Windows users hysterically complaining about this are not expecting Microsoft to behave in some outrageous way; they’re expecting Microsoft to behave as usual.

This is going to be interesting. I’m already thinking on how it would impact my gameplay.
The main concern for me is sci packs spoiling. Ideally they should be consumed in situ, so I’d consider moving the research to Gleba and ship other sci packs to it. This way, if something does spoil at least the spoilage is near where I can use it. Probably easier said than done - odds are that other planets have “perks” that would make centralising science there more convenient.
You’ll also probably want to speed up the production of the machines as much as possible, since the products inherit spoilage from the ingredients. Direct insertion, speed modules, upgrading machines ASAP will be essential there - you want to minimise the time between the fruit being harvested and outputting something that doesn’t spoil (like plastic or science).
Fruits outputting pulp and seeds also hint me an oil-like problem, as you need to get rid of byproducts that you might not be using. Use only the seeds and you’re left with the pulp; use only the pulp and you’re left with the seeds. The FFF hints that you can burn stuff, but that feels wasteful.

I don’t think that mass production is doing it alone, but that it’s a factor. It’s what prevents GameFreak from changing the core gameplay of the game; and without meaningful changes to core gameplay, they need to attract players through other ways.
And one of those ways is making the mons of a newer gen stronger than the ones of the gen before. (Another is introducing “gimmick mechanics” that get forgotten in the next gen.)
I also apologise for the tone. That was a knee-jerk reaction from my part; my bad.
(In my own defence, I’ve been discussing this topic with tech bros, and they rather consistently invert the burden of the proof. Often to evoke Brandolini’s Law. You probably know which “types” I’m talking about.)
On-topic. Given that “smart” is still an internal attribute of the blackbox, perhaps we could gauge better if those models are likely to become an existential threat by 1) what they output now, 2) what they might output in the future, and 3) what we [people] might do with it.
It’s also easier to work with your example productively this way. Here’s a counterpoint:
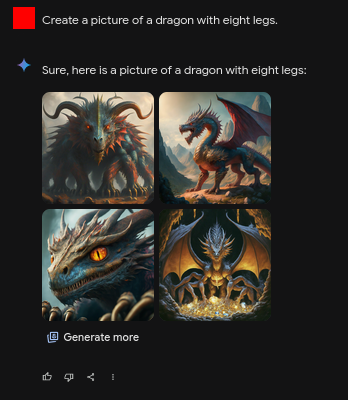




The prompt asks for eight legs, and only one pic was able to output it correctly; two ignored it, and one of the pics shows ten legs. That’s 25% accuracy.
I believe that the key difference between “your” unicorn and “my” eight-legged dragon is in the training data. Unicorns are fictitious but common in popular culture, so there are lots of unicorn pictures to feed the model with; while eight-legged dragons are something that I made up, so there’s no direct reference, even if you could logically combine other references (as a spider + a dragon).
So their output is strongly limited by the training data, and it doesn’t seem to follow some strong logic. What they might output in the future depends on what we add in; the potential for decision taking is rather weak, as they wouldn’t be able to deal with unpredictable situations. And thus their ability to go rogue.
[Note: I repeated the test with a horse instead of a dragon, within the same chat. The output was slightly less bad, confirming my hypothesis - because pics of eight-legged horses exist due to the Sleipnir.]
Neural nets
Neural networks are a different can of worms for me, as I think that they’ll outlive LLMs by a huge margin, even if the current LLMs use them. However, how they’ll be used is likely considerably different.
For example, current state-of-art LLMs are coded with some “semantic” supplementation near the embedding, added almost like an afterthought. However, semantics should play a central role in the design of the transformer - because what matters is not the word itself, but what it conveys.
That would be considerably closer to a general intelligence than to modern LLMs - because you’re effectively demoting language processing to input/output, that might as well be subbed with something else, like pictures. In this situation I believe that the output would be far more accurate, and it could theoretically handle novel situations better. Then we could have some concerns about AI being an existential threat - because people would use this AI for decision taking, and it might output decisions that go terribly right, as in that “paperclip factory” thought experiment.
The fact that we don’t see developments in this direction yet shows, for me, that it’s easier said than done, and we’re really far from that.
They’re even more exploration-heavy than Emerald. Roughly, the earlier the game, the bigger the focus on exploration, as hardware limitations didn’t allow much storytelling.
Also, I recommend playing their remakes instead of the original games; the originals are extremely buggy and have huge balance issues. (For example, there’s a shore in Red/Blue that you can use to catch Safari Zone mons. And Psychic mons are crazy overpowered - the only Ghosts in the region are partially Poison, there’s a lot of other Poison types, and since Gen1 was before the special split they got huge offensive and defensive capabilities.)
This screams FAITH (Filthy Assumptions Instead of THinking) from a distance, on multiple levels:
Furthermore, Gates in the quote is being disingenuous:
The answer addresses something far, far more specific than the main issue.
If I may, here’s my alternative solution for the problem, in the same style as Gates’:
Kill everyone between the North Pole and the Equator.
What do you mean, it would kill 85% people in the world? Well, you can’t make an omelet without breaking some eggs, right? Nobody that I know personally lives there, so Not My Problem®. (Just keep Japan, I need my anime to watch.)
…I’m being clearly sarcastic to deliver a point here - it’s trivially easy to underestimate issues affecting humankind, and problems associated with their solutions, if you are not directly affected by either. Gates is some billionaire bubbled around rich people; this sort of problem will affect the poor first, as the rich can simply throw enough money into their problems to make them go away.